Authors Agrawal et. al. (2024) provide a detailed overview of batching related choices made by three popular LLM serving systems: FasterTransformer, vLLM, and Orca, and discuss such choices' impact on latency-throughput tradeoff. They propose two techniques, (1) chunked prefills, and (2) stall-free batching, which improve inference performance.
LLM Inference: Overview
Inference happens in two phases, prefill followed by decode.
-
Prefill: We perform a forward pass for the user's input tokens, all of which are processed in parallel (this is possible because (1) we know the entire sequence of input tokens beforehand, and (2) we use a triangular mask which ensures \(\text{token}_t\) attends only to \(\text{token}_{1,\cdots, t-1}\)). This computes the first output token along with key-value states for each layer (the "KV Cache").
We need to load model weights just once from GPU HBM to GPU cache, and the cost of this load operation is amortized across all input tokens. We say that Prefilling has high "arithmetic intensity" as we can perform a large number of FLOPs for each byte of data loaded from the HBM.
-
Decode: We generate output tokens, one token at a time. In each time step, we perform a forward pass for one token (which is the output token generated in the previous step) and generate a new output token. In each step, we need to load (1) the KV Cache, and (2) model weights, from the GPU HBM to GPU cache. Due to these memory accesses required in every time step, Decoding has a low arithmetic intensity.
We say that Decode is "memory bound", which means its execution time is bottlenecked by the time it takes to fetch data (weights, activations, KV cache) from memory. The time spent in computation on the GPU is less than this memory fetch time.
Impact of Batching on Prefill and Decode
Prefill's parallel processing of all input tokens ensures that GPU compute is fully utilized (i.e., all GPU cores are busy). Consequently, batching different input prompts together has minimal impact on throughput (measured by tokens processed per second), since we were already using GPU compute efficiently. On the other hand, larger batches immensely improve Decoding throughput (tokens generated per second). The cost of loading model weights from HBM is amortized across all prompts in a batch, and so larger the batch size, higher is the arithmetic intensity of batched decoding (for each byte of model weights loaded from HBM, we can perform more FLOPs because we'll be using the same weights for computations across requests in the batch).
Figure 3. from the paper below shows impact of batch size on throughput for Mistral 7B on a single A100, for a prompt length of 1024 tokens. Authors make two observations: (1) the y-axis are different and this shows Prefill computation is much faster than Decode, and (2) batching boosts Decode throughput almost linearly.
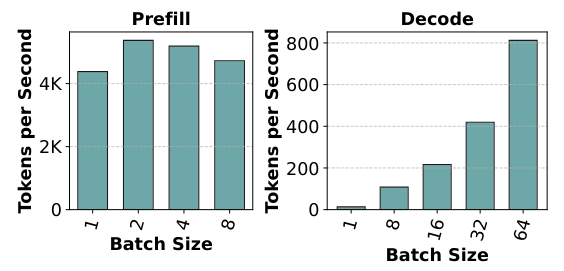
Batch size can only be increased up to a certain limit (as noted in this NVIDIA blog) because larger batches require more memory to hold KV Caches of requests in the batch, and GPU HBM is finite. E.g. KV Cache for a 100k token sequence for Llama-3 70B may consume ~33GB, which authors note is still 8x smaller than Llama-2 70B (because Llama-3 uses Grouped Query Attention). A few other techniques which help fit larger batches are (1) PagedAttention which prevents memory wastage due to KV Cache fragmentation, and (2) model parallelism which shards model weights across multiple GPUs.
Runtime Contribution of Various Transformer Operations
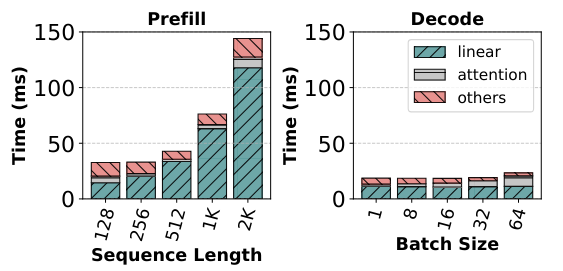
Figure 4 from the paper shows that linear layers contribute to more than 80% of runtime. Authors note that further that because of Decode's low arithmetic intensity, the cost of linear layers for 1 Decode token ~ 128 Prefill tokens.
LLM Serving Systems: Scheduling Choices
LLM serving systems receive concurrent requests, and to achieve high GPU utilization (we always want to do parallel computations on GPUs - that's how GPUs accelerate computation), they try to batch requests together. Authors classify serving systems into:
-
Decode Prioritizing: Batch together requests ("request-level batching") and first perform Prefill for all requests, and then perform Decode. The batch is considered completed once all requests are done decoding. While a batch is being processed, any new requests received by the system are not scheduled for Prefill.
Such scheduling optimizes for latency (as measured by time-between-tokens or TBT) because new requests do not affect executing of ongoing requests. However this impacts throughput because new requests will have to wait for the longest ongoing request to finish. FasterTransformer is based on such scheduling.
-
Prefill Prioritizing: Schedule Prefill phase of new requests in a running batch as soon as GPU memory is available. This improves throughput because it allows a larger batch size for subsequent decoding. Orca and vLLM use such scheduling along with "iteration-level batching" where requests can dynamically enter and exit a batch after each model iteration. One difference is that Orca supports hybrid batches containing both Prefill and Decode requests, while vLLM allows only one type of requests (Prefill or Decode) in batch.
In the case of vLLM, any incoming requests will be scheduled for Prefill before the Decode step of ongoing requests begins. Since input prompts can be arbitrarily long, Prefill computation can take long while, delaying Decode and leading to a higher TBT. Authors call this a "generation stall". While Orca allows hybrid batches, it doesn't prevent generation stalls because a hybrid batch containing long Prefill requests will take a long time to execute.
Sarathi-Serve
Authors propose Sarathi-Serve, an LLM serving system which "provides high throughput with predictable tail latency" by using "chunked prefills" and "stall-free batching".
-
Chunked Prefills: The low arithmetic intensity of Decode can be inreased by creating hybrid batches with both Prefill and Decode requests. This does not work in practice as input prompts are usually quite long, and their Prefill computation can take a while and increase TBT. Authors propose "chunked prefills" which compute long prefills in small chunks over several iterations. They note that Prefill requests with modest sequence lengths can saturate GPU compute, e.g. Figure 4 from the paper, reproduced above, shows that sequences of 512 tokens are enough. Thus, we can breaking input sequences which are thousands of tokens long, into chunks small enough to saturate GPUs.
-
Stall-free Batching: Sarathi aims to use what authors term the "arithmetic intensity slack" (in other words, idle GPU cores) during Decode, to execute Prefills. This is in contrast to vLLM and Orca which stall existing Decodes to execute Prefills. To achieve this, Sarathi first computes a token budget - the maximum number of tokens that can be executed in a batch based on a user specified maximum TBT. Next, in every scheduling iteration, Sarathi decides which requests to include in a batch, based on the computed token budget.
-
Token Budget Computation: The budget depends on two competing factors. The first is TBT latency - fewer Prefill tokens imply lower latency. The second factor is Prefill Overhead. Attention for a chunk requires loading KV Caches of all chunks in that prompt, and so a small chunk size will lead to repeated HBM accesses of the same data, even though computation cost remains the same. This creates an overhead for Prefill. Authors observe that Prefill remains compute-bound even with small chunk sizes.
To compute the actual budget, authors recommend a one-time profiling with different number of tokens to determine the maximum number that would fit in a batch while meeting TBT targets.
-
Batch Construction: In each iteration, first pack all the ongoing Decodes in a batch. Then add any partially complete Prefill request to the batch. New requests are added only after all existing requests have been accommodated. We compute the leftover token budget for the batch, and then determine the maximum chunk size that can be accommodated within that budget.
-